Verteilte Streamdatenanalyse-Architekturen mit Splunk
Verteilte Architekturen zur Streamdatenanalyse
am Beispiel von Splunk-Indexer-Clustern
Plattformen zur Streamdatenanalyse sollen möglichst sofort und pausenlos aktuelle Einblicke in die fortlaufend gesammelten Daten ermöglichen.
So ist in der industriellen Fertigung die Information über einen wahrscheinlichen Maschinenausfall nur nützlich, wenn diese erfolgt, bevor die Maschine ausfällt. Dafür ist ein kontinuierliches Prognostizieren der Ausfallwahrscheinlichkeit, beispielsweise durch Bewertung von Temperaturverläufen und Stromverbräuchen, unerlässlich. Zwingend muss hierbei auch die genutzte Analyseplattform sowohl schnell als auch hochverfügbar aktuelle Ergebnisse liefern. Um weiterhin auch während Upgrades oder kleinerer Ausfälle von Komponenten der Analyseplattform die Funktion zu gewährleisten, bieten daher viele Produkte Möglichkeiten zum Clustering.
Rollen im Cluster
Im Folgenden soll die Cluster-Architektur am Beispiel von verteilten Splunk Umgebungen erläutert werden. Die einzelnen Instanzen des Splunk-Clusters basieren alle auf der gleichen Installation und werden lediglich unterschiedlich konfiguriert um spezielle Rollen zu erfüllen.
So verwaltet der Master Node die Metadaten des Clusters während die als Peer Nodes bezeichneten Indexer die Speicherung der Daten übernehmen, welche von den Forwardern empfangen werden. Searchheads ermöglichen den Anwendern dann, diese Daten zu durchsuchen und unter anderem Dashboards und automatische Benachrichtigungen zu erstellen.
Diese Unterteilung in spezielle Rollen ermöglicht zielgerichtetes Loadbalancing. Kommen mehr Daten hinzu, helfen zusätzliche Peer Nodes bei deren Verarbeitung. Werden es sehr viele Nutzer, sollte man über Search Head Clustering nachdenken. Dabei wird einer der Searchheads zum Captain ernannt und verwaltet die Metadaten der Searchheads, wie es der Master Node für die Indexer tut. Zunächst möchten wir uns auf das Clustern der Indexer konzentrieren und Master Node sowie Peer Node genauer betrachten.
Master, Peer Node und Replikation
Beginnen wir mit dem Herzstück, dem Master Node. Er koordiniert beispielsweise die Replikation der in zeitliche Einheiten, Buckets, unterteilten Daten zwischen den Peer Nodes und kommuniziert den Searchheads, wo Daten liegen. Auch kann er zum Konfigurieren und Verwalten der Peer Nodes genutzt werden und koordiniert die Aktivitäten bei Ausfall eines Peers. Fällt ein Peer Node aus, so sind dessen Daten nicht mehr durchsuchbar. Da aber, dank Replikation im Cluster, Replikate dieser Daten auf anderen Nodes verfügbar sind, werden diese nochmals kopiert oder durchsuchbar gemacht, bis Such- und Replikationsfaktor wieder erfüllt sind.
Der Replikationsfaktor bestimmt, wie viele Kopien der Rohdaten auf verschiedenen Peer Nodes im Cluster vorzuhalten sind. Diese Rohdaten können von Splunk nicht durchsucht werden und dienen lediglich der Datenwiederherstellung bei Ausfall eines Peer Nodes. Der Suchfaktor legt fest, wie viele Kopien dieser Rohdaten darüber hinaus auch durchsuchbar sein sollen. Dafür werden Indexstrukturen zu den Rohdaten angelegt, wodurch Splunk diese effizient zu durchsuchen vermag. Allerdings hat dies auch einen Preis: Die Indexstrukturen belegen Speicherplatz. Typischerweise belegen die Rohdaten 15% des Speicherplatzes der Originaldaten (durch Komprimierung). Die Indexdaten benötigen hingegen circa 35%. Folglich ist eine durchsuchbare Kopie rund zwei Drittel speicherplatzintensiver als eine reine Kopie der Rohdaten. Dafür können die Daten auch für die Suche genutzt werden, was bei vielen parallel laufenden Suchanfragen durch die Lastverteilung zu höherer Suchperformance führen kann. Beide Faktoren können administrativ konfiguriert werden.
Die Peer Nodes empfangen folglich die Nutzdaten und speichern diese inklusive effizienter Zugriffsstrukturen. Die Searchheads verteilen ihre Anfragen auf die Peer Nodes, welche jeweils ihre Daten durchsuchen und die Teilergebnisse zurückliefern. Die Searchheads fassen dann die Zwischenergebnisse zusammen und verarbeiten die Suchergebnisse final. Untereinander replizieren die Peer Nodes ihre Daten und melden den Status an den Master Node, um Performanceverbesserungen zur Suchzeit sowie Ausfallsicherheit zu erreichen.
Konfiguration eines Splunk-Clusters
Das Aufsetzen eines Indexer Clusters ist in Splunk Enterprise Version 8 sehr komfortabel. Die Weboberflächen der einzelnen Instanzen bieten unter Einstellungen, Indexer Clustering entsprechende Konfigurationsoptionen. Zuerst werden auf dem Master Node Replikations- und Suchfaktor eingestellt und der Pass4SymmKey vergeben. Letzterer muss neben der Adresse des Master Nodes auf jedem Peer eingegeben werden, damit dieser sich als Teil des Clusters am Master anmelden kann. Weiterhin wird der Replikationsport jedes Peer Nodes eingestellt. Abschließend wird auch auf dem Searchhead der Master Node mitsamt Pass4SymmKey hinterlegt, damit dieser das Cluster durchsuchen kann. Die Pass4SymmKeys werden dabei jeweils verschlüsselt gespeichert.
Analog ist die Konfiguration über Konsolenkommandos oder Konfigurationsdateien möglich. Diese ermöglichen darüber hinaus ein Feintuning der Clustereinstellungen, wie beispielsweise der Replikationsparameter. Auch ein Rolling-Upgrade des Indexer-Clusters im laufenden Betrieb kann mittels Konsole realisiert werden. Bei Anpassung des Pass4SymmKeys via Konfigurationsdatei wird dieser beim Neustart der Instanz verschlüsselt, weshalb er auch nicht mit "$1$" beginnen darf, da dies die erfolgte Verschlüsselung kennzeichnet.
Komplexere Umgebungen
In unserer zweitägigen Schulung zur Splunk-Administration (Link) lernen Sie in praktischen Übungen viele weitere Details zur Konfiguration eines Indexer-Clusters, inklusive beispielsweise dem zentralen Monitoring und Management der Forwarder oder der automatischen Erkennung neuer Indexer.
Soll das Cluster über mehrere, ggf. geographisch verteilte, Standorte verteilt werden, so macht die Konfiguration eines Multisite-Clusters Sinn. Durch Zuordnung der Peer Nodes und Searchheads zu den Sites können diese bevorzugt die Peer Nodes ihrer eigenen Site durchsuchen. Somit werden Netzwerklatenzen vermieden. Such- und Replikationsfaktor werden ebenfalls je Site eingestellt.
Daraus lassen sich letztlich komplexe Architekturen zusammenstellen. So kann ein Searchheadcluster mehrere Indexcluster durchsuchen. Die Indexcluster können dabei auch unabhängig voneinander, z.B. auf verschiedenen Kontinenten, laufen. Gern unterstützen wie Sie beim Betrieb komplexer Splunk-Umgebungen oder der Entwicklung gut skalierender Apps.
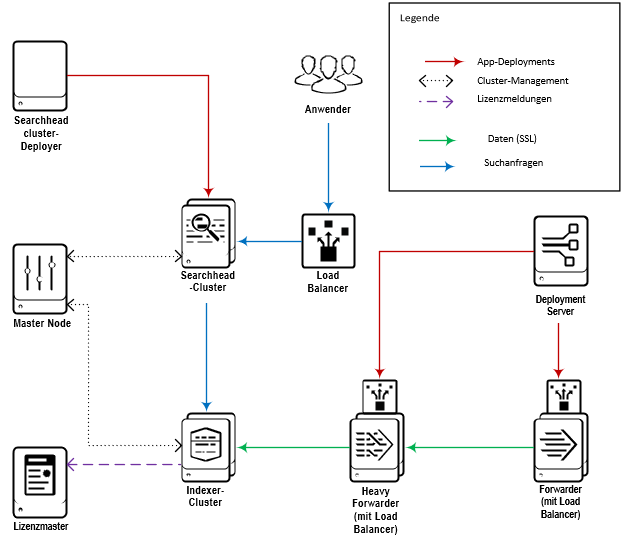
Die Universal Forwarder könnten ihre Daten auch direkt an die Indexer senden und so beispielsweise vom automatischen Indexer Discovery profitieren.
In diesem Beispiel werden die Daten von den Forwardern zunächst an eine Zwischenschicht aus Heavy Forwardern gesandt, wo sie analysiert und bereinigt werden. Um die Indexer zu entlasten, geschieht dies vorgelagert. Heavy Forwarder unterstützen zusätzliche Datenquellen und die tiefere Analyse des Datenstroms.

Kommentare
Keine Kommentare